Distributed Data Parallel
This is the modern pytorch method to do data parallel. which is a ring synchronization method. NCCL provides good optimization for DDP.
Steps:
-
Assume we have 4 nodes
-
Broke the gradients into n chunks
- and then doing steps below
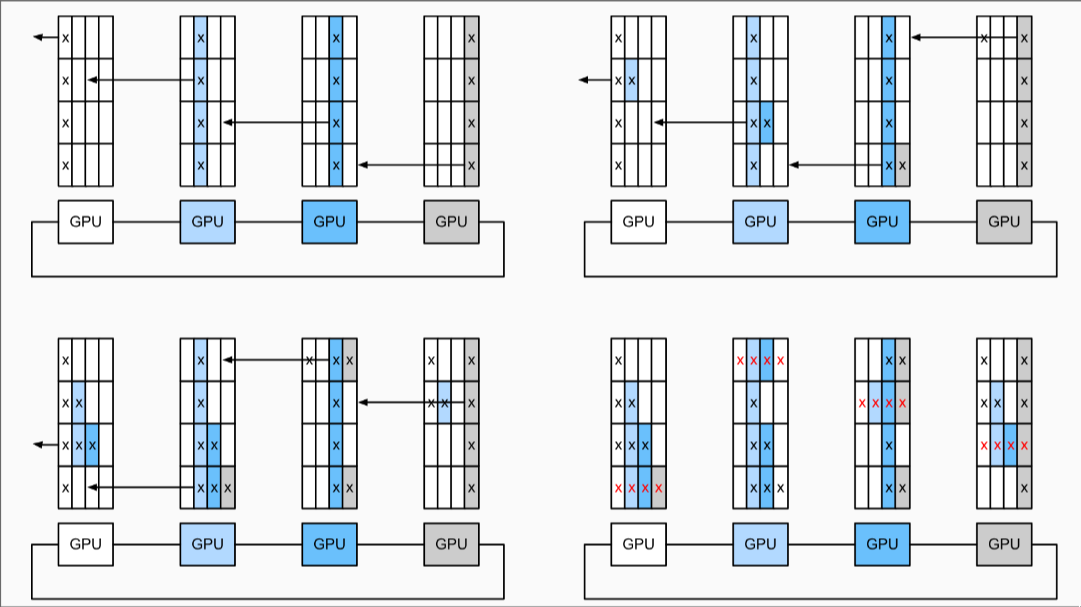
-
Untile every GPU's n chunks has four red cross.
-
Then the total time improve from DP's n to (n-1)/n which is 1
-
This is an Ring-AllReduce step.
- Support Multi-node well
Learn what is single-node multi-GPUs
Learn what is multi-node multi-gpus